Like so many data sets there are some data clean up challenges. The first is the use of excel, which is not a problem, but the authors decided to add considerable headers, and unusual formats to the summary tables. Here is my attempt to get one of the first data files cleaned up and working. One big problem is changing $1,000.00 into 1000.00, I have some code below, but would appreciate any help in making my code better. Below are the summary graphs of the data:


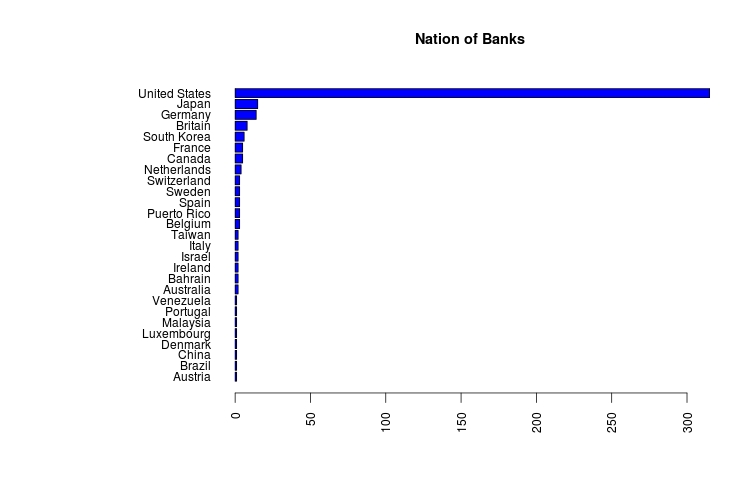





Below is my R code:
#Fed Data library(stringr) fed.01<-read.csv(file.choose(), header=T) summary(fed.01) #Cleaning up the Data- removed the $ sign and the ',' in 1,000 average<-str_sub(fed.01$Average.Daily.Balance..in.Millions.of.U.S..Dollars., start=2, end=-1) average<-as.numeric(gsub(",", '', average)) fed.02<-cbind(average, fed.01) #Exploritory Graphs hist(fed.02$Days.in.Debt, main='Histogram of Days in Debt', col='red', xlab='no. Days in Debt') years.debt<-fed.02$Days.in.Debt/365 hist(years.debt, main='Histogram of Years in Debt', col='red', xlab='no. Years in Debt', breaks=15) #Bar graphs the the data #The country of origin par(las=2, mar=c(5,12,4,2), mfrow=c(1,1)) country<-sort(table(fed.01$Country)) barplot(country, main='Nation of Banks', col='blue', horiz=TRUE) #Type of Bank or Industry par(las=2, mar=c(5,17,4,2), mfrow=c(1,1)) industry<-sort(table(fed.01$Industry)) barplot(industry, main='Type of Industry', col='blue', horiz=TRUE) #Organizations with average balances greater than $5 billion five.bill<-subset(fed.02, average>5000) par(las=2, mar=c(5,19,4,2), mfrow=c(1,1)) barplot(sort(five.bill$average),names.arg=five.bill$Company, main='Companies With Average Daily Balance Greater than $5 Billion', col='blue', hor=TRUE) #Organizations with debt more then 730 days (2 years) year.comp<-subset(fed.02, Days.in.Debt>730) par(las=1, mar=c(5,20,4,2)) barplot(sort(year.comp$Days.in.Debt), names.arg=year.comp$Company, main='Companies With Days of Debt Greater than 730 Days (2 Years) days', col='red', hor=TRUE, xpd=FALSE, xlim=c(720, 830)) par(las=0, mar=c(5,4,4,2)) #Regression of Days in Debt to Ave. Daily Balance #ploted the data, the r2 is poor, and the slop is positive, #nothing to get too excited about, took the log plot(fed.02$Days.in.Debt, fed.02$average, xlab='Days in Debt', ylab='Ave. Daily Balance', main='Scatter Plot: Daily Balance and Days in Debt') lm.01<-lm(fed.02$average~fed.02$Days.in.Debt) abline(lm.01) summary(lm.01) #log of fed$average to reduce the outliers log.aver<-log(fed.02$average) plot(fed.02$Days.in.Debt, log.aver, xlab='Days in Debt', ylab='Log of Ave. Daily Balance', main='Scatter Plot: Log Daily Balance and Days in Debt') lm.02<-lm(log.aver~fed.02$Days.in.Debt) abline(lm.02) summary(lm.02)
thanks for pointing out this source, looks interesting.
ReplyDeletestr_replace_all may be a better function for getting rid of $ , and spaces (see usage in the code below).
regarding the file on the individual companies the following script may do the trick:
library(stringr)
library(lubridate)
library(reshape2)
setwd("~/prj/2012/01theFedBank/") # path to wherever the zip file resides
zFile <- "201112221200_fed_data_files_for_public_release.zip"
dat <- read.csv(unz(zFile,"1b_Company_Index_1.csv"),stringsAsFactors=F)
names(dat) <- c("id","fileName","company","ticker","peakDate","peakAmount",
"country","industry","capitalRaised","average","daysInDept")
DAT <- NULL
for (i in 1:length(dat$fileName)) {
print(i)
tmp <- read.csv(unz(zFile,dat$fileName[i]),skip=12,header=TRUE)
names(tmp)[1:4] <- c("date","balance","stock","pmc")
#tmp <- tmp[,-4]
tmp$company <- dat$company[i]
tmp <- melt(tmp,id.var=c("date","company"))
DAT <- rbind(DAT,tmp)
}
DAT$date <- mdy(as.character(DAT$date))
DAT$value <- as.numeric(str_replace_all(DAT$value,"([%$, ])", ""))
einar hjörleifsson
einar hjörleifsson
ReplyDeletethanks for the code. I am working my way through it, seems much better. Thanks.
Outlier
You guys make it really easy for all the folks out there.
ReplyDeleteunsecured loans online
Your site is very informative and your articles are wonderful.
ReplyDeletepay day loan application
This is nice post which I was awaiting for such an article and I have gained some useful information from this site related loan. Thanks for sharing this information.
ReplyDeleteThanks BY:
Easy Payday Loans
Loans for Payday
Hi, i read this post & I found informative points regarding loan please keep posting in future I appreciate you thanks 12 month loans, one year loans, 12 month loan, 1 year loans, 1 year loan. http://www.12monthcashloans.me.uk
ReplyDeleteIt is recommended that you should compare the existing offers with your favorite ones because the continuous influx of financial institutions has developed a competitive atmosphere among lenders. http://yesloans1.org.uk
ReplyDeleteVery nice post its really useful for all borrowers.
ReplyDelete12 month payday loans
The chart preparation is very nice.
ReplyDeleteLoans for 12 months
Thousands of people use us to obtain payday online loans and all of them do it for different reasons
ReplyDeleteLoans for 12 months
Many people use us to acquire pay day loan online financial loans and all of them do it for different reasons
ReplyDeletefast cash loans
"This blog is further than my expectations. Nice work guys!!! The quality of your articles and contents is great.
ReplyDelete"
12 month loans
Nice Blog Useful details.
ReplyDeleteAutomatic Enrolment & Workplace Pensions Bristol
Thanks fellow your posts are really very good for me since it make good sense for me. payday loan
ReplyDeleteشركة الطيب
ReplyDeleteشركة تنظيف بمكة
شركة نقل اثاث بمكة
شركة تنظيف منازل بمكة
شركة تنظيف خزانات بمكة
شركة مكافحة حشرات بمكة
شركة تنظيف شقق بالدمام
شركة نقل اثاث بالدمام
myfedloan
ReplyDeletemyfedloan contact
metdental